Deploy a Highly-Available MongoDB Replica Set on AWS
Jul 24, 2016
Ah, MongoDB. Arguably the leading NoSQL database available today, it makes it super easy to start hacking away on projects without having to worry about table schemas, while delivering extremely fast performance and lots of useful features.
However, running a scalable, highly-available MongoDB cluster is a whole 'nother story. You need a good understanding of how replica sets work and be familiar with the inner workings of MongoDB. And you need to set up tooling to constantly monitor your cluster for replication lag, CPU usage, disk space utilization, etc, as well as periodically back up your databases to prevent data loss.
While solutions such as Compose and MongoDB Atlas could save you the time and effort required in setting up and maintaining your own cluster, these solutions give you less control in the end -- your data and uptime is in another company's hands, in addition to AWS.
I have not been fortunate with these kinds of solutions -- I experienced several unexpected instances of downtime that my services cannot tolerate. When things went wrong, all I could do was open a support ticket and wait (sometimes days!) until the engineers would be able to resolve the issue.
If the database is the single most important part of your application, leave the controls in your hands. Setting up our own cluster is actually not that hard, let's get to it!
Note: This is an extremely comprehensive guide, make sure you have at least an hour to spare.
Replica Sets
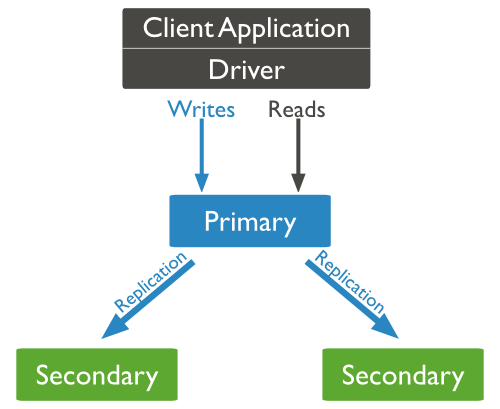
So, what is a replica set? Put simply, it is a group of MongoDB servers operating in a primary/secondary failover fashion. At any point there can only be one primary member within the replica set, however, you can have as many secondaries as you want. All secondaries actively replicate data off of the current primary member so that if it fails, one of them will be able to take over quite seamlessly as the new primary. They do this by examining the primary member's oplog, a file that contains a log of every single write query performed against the server.
The more secondaries you have, and the more spread out they are over availability zones or regions, the less chance your cluster will ever experience downtime.
Your application will usually only run queries against the primary member in the replica set.
Replica Set Members
The most minimal replica set setup must have at least three healthy members to operate. One member will serve as the primary, another as the secondary, and the third as an arbiter.
Arbiters are members that participate in elections in order to break ties and do not actually replicate any data. If a replica set has an even number of members, we must add an arbiter member to act as a tie-breaker, otherwise, when the primary member fails or steps down, a new primary will not be elected!
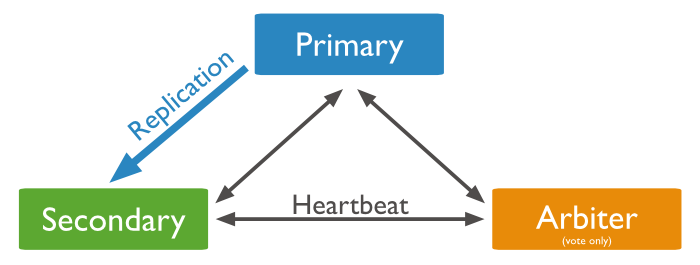
This requirement was put in place to prevent split-brain scenarios where 2 secondary members in a cluster who can't communicate with each other decide to vote for themselves, causing them both to become primaries, leading to data inconsistency and a plethora of other problems.
You can also avoid an arbiter by simply adding another secondary instead. All you really need is an odd number of members for elections to be held properly. However, an extra secondary will cost you more than an arbiter.
Instance Types
The data members in the replica set should be deployed to an instance type that suits your application's needs. Depending on your traffic, queries per second, and data size, you'll need to pick a matching instance type to accommodate that workload. The good news is that you can upgrade your instance type in the future in a matter of minutes and without downtime by utilizing replica set step downs, as we'll see later on.
I usually go with either m3.medium or m4.large for a production application with about 50 queries per second. If you're just starting to work on a new project, even t2.nano will do just fine. Note that t2 instances have limited CPU credits and should not be used for high-throughput deployments, since their compute capacity is unpredictable.
It is absolutely fine to host the arbiter member on a weak instance type such as t2.nano, since all it will ever do is participate in elections.
Instance Storage
Always provision General Purpose (gp2) storage for MongoDB data members as the underlying disk is a network-attached SSD which will provide better read/write speeds than magnetic storage.
Note that if you select an m4.large instance type or larger, you'll also get EBS optimization which will provide your instance with dedicated IO throughput to your EBS storage, increasing the number of queries per second your cluster will be able to handle, as well as preventing replication lag to your secondaries.
In addition, if you want to maximize your read/write IO throughput rate and your workload is big enough, consider using Provisioned IOPS (io1) storage. This can be quite expensive though, depending on the number of IOPS you provision, so make sure you understand the pricing implications.
Get Started
The first step in setting up the replica set is to prepare the instances for running MongoDB and to make sure you have your own domain name.
Provision the Instances
Spin up 3 brand-new Ubuntu 14.04 LTS instances in the EC2 console, making sure to set up each one in a different availability zone, for increased availability in case of service outage in one AZ. Provision enough storage to fit your data size, and select the appropriate instance types for each replica set member. Also, create an EC2 key pair so that you can SSH into the instances.
Create a new security group, mongodb-cluster, and configure all three instances to use it. Allow SSH on port 22 from your IP only and port 27017 from the mongodb-cluster security group (sg-65d4d11d for example) as well as from your IP address, so that both you and the replica set members will be able to connect to each other's mongod process listening on port 27017.
Next, request 3x Elastic IPs and attach them to each instance, so that your members will maintain the same public IP throughout their entire lifetime.
Finally, label each instance you created as follows, replacing example.com with your domain name:
- Data - db1.example.com
- Data - db2.example.com
- Arbiter - arbiter1.example.com
Setup DNS Records
Head over to your domain's DNS management interface and add CNAME records for db1, db2, and arbiter1. For each record, enter each instance's Public DNS hostname, visible in the EC2 instances dashboard.
Pro tip: When your EC2 servers perform a DNS query to translate the Public DNS hostname to an IP, the EC2 DNS server will actually return the private IP address of the instance since it's in the same VPC as the instance performing the DNS query, thereby improving latency and bandwidth between the replica set members, and saving you from paying bandwidth costs.
Configuring the Servers
Before we can get the replica set up and running, we need to make a few modifications to the underlying OS so that it behaves nicely with MongoDB.
Set the Hostname
SSH into each server and set its hostname so that when we initialize the replica set, members will be able to understand how to reach one another:
sudo bash -c 'echo db1.example.com > /etc/hostname && hostname -F /etc/hostname'Make sure to modify db1.example.com and set it to each server's DNS hostname. The first command will set the server's hostname in /etc/hostname, the second will apply it without having to reboot the machine.
Repeat this step on all replica set members.
Increase OS Limits
MongoDB needs to be able to create file descriptors when clients connect and spawn a large number of processes in order to operate effectively. The default file and process limits shipped with Ubuntu are not applicable for MongoDB.
Modify them by editing the limits.conf file:
sudo nano /etc/security/limits.confAdd the following lines to the end of the file:
* soft nofile 64000
* hard nofile 64000
* soft nproc 32000
* hard nproc 32000
Next, create a file called 90-nproc.conf in /etc/security/limits.d/:
sudo nano /etc/security/limits.d/90-nproc.confPaste the following lines into the file:
* soft nproc 32000
* hard nproc 32000
Repeat this step on all replica set members.
Disable Transparent Huge Pages
Transparent Huge Pages (THP) is a Linux memory management system that reduces the overhead of Translation Lookaside Buffer (TLB) lookups on machines with large amounts of memory by using larger memory pages.
However, database workloads often perform poorly with THP, because they tend to have sparse rather than contiguous memory access patterns. You should disable THP to ensure best performance with MongoDB.
Run the following commands to create an init script that will automatically disable THP on system boot:
sudo nano /etc/init.d/disable-transparent-hugepagesPaste the following inside it:
#!/bin/sh
### BEGIN INIT INFO
# Provides: disable-transparent-hugepages
# Required-Start: $local_fs
# Required-Stop:
# X-Start-Before: mongod mongodb-mms-automation-agent
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Disable Linux transparent huge pages
# Description: Disable Linux transparent huge pages, to improve
# database performance.
### END INIT INFO
case $1 in
start)
if [ -d /sys/kernel/mm/transparent_hugepage ]; then
thp_path=/sys/kernel/mm/transparent_hugepage
elif [ -d /sys/kernel/mm/redhat_transparent_hugepage ]; then
thp_path=/sys/kernel/mm/redhat_transparent_hugepage
else
return 0
fi
echo 'never' > ${thp_path}/enabled
echo 'never' > ${thp_path}/defrag
unset thp_path
;;
esacMake it executable:
sudo chmod 755 /etc/init.d/disable-transparent-hugepagesSet it to start automatically on boot:
sudo update-rc.d disable-transparent-hugepages defaultsRepeat this step on all replica set data members.
Turn Off Core Dumps
MongoDB generates core dumps on some mongod crashes. For production environments, you should turn off core dumps since generating them can take minutes or even hours in case your workload is large.
sudo nano /etc/default/apportFind:
enabled=1Replace with:
enabled=0Configure the Filesystem
Linux by default will update the last access time when files are modified. When MongoDB performs frequent writes to the filesystem, this will create unnecessary overhead and performance degradation. We can disable this feature by editing the fstab file:
sudo nano /etc/fstabAdd the noatime flag directly after defaults:
LABEL=cloudimg-rootfs / ext4 defaults,noatime,discard 0 0Read Ahead Block Size
In addition, the default disk read ahead settings on EC2 are not optimized for MongoDB. The number of blocks to read ahead should be adjusted to approximately 32 blocks (or 16 KB) of data. We can achieve this by adding a crontab entry that will execute when the system boots up:
sudo crontab -eChoose nano by pressing 2 if this is your first time editing the crontab, and then append the following to the end of the file:
@reboot /sbin/blockdev --setra 32 /dev/xvda1Make sure that your EBS volume is mounted on /dev/xvda1. Save the file and reboot the server:
sudo rebootRepeat this step on all replica set data members.
Verification
After rebooting, you can check whether the new hostname is in effect by running:
hostnameCheck that the OS limits have been increased by running:
ulimit -u # max number of processes
ulimit -n # max number of open file descriptorsThe first command should output 32000, the second 64000.
Check whether the Transparent Huge Pages feature was disabled successfully by issuing the following commands:
cat /sys/kernel/mm/transparent_hugepage/enabled
cat /sys/kernel/mm/transparent_hugepage/defragFor both commands, the correct output resembles:
always madvise [never]Check that noatime was successfully configured:
cat /proc/mounts | grep noatimeIt should print a line similar to:
/dev/xvda1 / ext4 rw,noatime,discard,data=ordered 0 0In addition, verify that the disk read-ahead value is correct by running:
sudo blockdev --getra /dev/xvda1It should print 32.
Install MongoDB
Run the following commands to install the latest stable 3.4.x version of MongoDB:
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 0C49F3730359A14518585931BC711F9BA15703C6
echo "deb [ arch=amd64 ] http://repo.mongodb.org/apt/ubuntu trusty/mongodb-org/3.4 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.4.list
sudo apt-get update
sudo apt-get install -y mongodb-orgThese commands will also auto-start mongod, the MongoDB daemon. Repeat this step on all replica set members.
Configure MongoDB
Now it's time to configure MongoDB to operate in replica set mode, as well as allow remote access to the server.
sudo nano /etc/mongod.confFind and remove the following line entirely, or prefix it with a # to comment it out:
bindIp: 127.0.0.1Next, find:
#replication:Add the following below, replacing example-replica-set with a name for your replica set:
replication:
replSetName: "example-replica-set"Finally, restart MongoDB to apply the changes:
sudo service mongod restartMake these modifications on all of your members, making sure to specify the same exact replica set name when configuring the other members.
Initialize the Replica Set
Connect to one of the MongoDB instances (preferably db1) to initialize the replica set and declare its members. Note that you only have to run these commands on one of the members. MongoDB will synchronize the replica set configuration to all of the other members automatically.
Connect to MongoDB via the following command:
mongo db1.example.comInitialize the replica set:
rs.initiate()The command will automatically add the current member as the first member of the replica set.
Add the second data member to the replica set:
rs.add("db2.example.com")And finally, add the arbiter, making sure to pass in true as the second argument (which denotes that the member is an arbiter and not a data member).
rs.add("arbiter1.example.com", true)Verify Replica Set Status
Take a look at the replica set status by running:
rs.status()Inspect the members array. Look for one PRIMARY, one SECONDARY, and one ARBITER member. All members should have a health value of 1. If not, make sure the members can talk to each other on port 27017 by using telnet, for example.
Setup Log Rotation
By default, MongoDB will fill up the /var/log/mongodb/mongod.log file with gigabytes of data. It will be very hard to work with this log file if we do not set up log rotation in advance.
Install logrotate as follows:
sudo apt-get install logrotateConfigure log rotation for MongoDB:
sudo nano /etc/logrotate.d/mongodPaste the following contents:
/var/log/mongodb/*.log {
daily
rotate 5
compress
dateext
missingok
notifempty
sharedscripts
copytruncate
postrotate
/bin/kill -SIGUSR1 `cat /var/lib/mongodb/mongod.lock 2> /dev/null` 2> /dev/null || true
endscript
}This will set up daily log rotation for mongod.log as well as send the SIGUSR1 signal to mongod when the log file is rotated so that it starts writing to the new log file.
Replica Set Administration
Now that your replica set is highly-available and healthy, let's go over how to manage it.
Connecting to Your Replica Set
To connect to any member of the replica set, simply run:
mongo db1.example.comReplace db1.example.com with any of the replica set member hostnames.
To send queries to your replica set from your application, simply use a MongoDB driver along with the following connection string:
mongodb://db1.example.com,db2.example.com/db-name?replicaSet=example-replica-setMake sure to replace example.com with your domain, db-name with the database you want to run queries against, and example-replica-set with the replica set name you configured in mongod.conf.
Performing Maintenance on the Replica Set
If you want to perform some kind of maintenance on a member of the replica set, make sure it's a secondary member. You do not want to shut down the primary member without stepping down and letting another secondary become the primary first.
Run the following command on the secondary member's mongo shell:
db.shutdownServer()Feel free to reboot the instance, modify its instance type, add more storage, provision more IOPS, etc. When you're done, simply start up the server and make sure mongod is running. The secondary member will catch up to the primary by examining its oplog and replicating anything it missed during its downtime window.
One thing to note though, is that you should not shut down secondaries for too long, otherwise, the primary's oplog will be truncated and they won't be able to catch up. Not the end of the world, but this will require you to perform a full resync of the secondary member(s) which might take time.
When you're done performing maintenance on all of the secondaries in the replica set, make sure all members of the replica set are healthy and then issue the following command on the primary member's mongo shell to ask it to step down and let another secondary take its place:
rs.stepDown()An election will then take place and the replica set members will vote for a new primary member. This can take anywhere from 10 to 50 seconds. During the election, the replica set will be unavailable for writes, since there is no primary member while voting takes place. Assuming you have an odd number of members, and there are healthy secondary members, a new primary will be elected and the replica set will be writable again.
Surviving Step Downs
Your application must be prepared to deal with step downs by queueing up the writes and reattempting them when the new primary has been elected.
This can easily be achieved with a Node.js package I developed called monkster which abstracts this for you automatically by implementing a retry mechanism when the replica set is unavailable due to a missing primary or other temporary network error.
Automated Backups
It's a good idea to set up a mechanism to automatically back up your database(s) every day to Amazon S3. If you accidentally delete an entire collection, secondaries will replicate that change and delete it locally as well, so backups will protect you from human error.
Check out mongodb-s3-backup.sh, a shell script I created that will automatically back up one of your databases to S3. You can configure it to run on an arbiter, for example, and have it read the data from a secondary, to avoid impacting the primary's performance. Read the gist for further instructions.
Replica Set Monitoring
It's important to constantly monitor your replica set to avoid downtime or other problematic situations caused by network issues or insufficient resources.
The following should be monitored via a script:
- The health status of the replica set (available via
rs.status()) - The health status of each replica set member, from the point of view of each member
- The minimum number of replica set members (should be 3 or more)
- The number of replica set members should be odd, not even
- The existence of a primary replica set member (this may fail if an election is in progress)
- The last heartbeat timestamp from one member to another being less than 3 minutes ago from the point of view of all members
- The oplog date on secondary members, which indicates if they've fallen behind on replication (it should not exceed 15 minutes ago)
- The remaining disk space does not exceed 80% on each and every member
- A recent S3 backup exists in case things go south
I developed a Node.js package that monitors most of these for you called mongomonitor, be sure to check it out!
That's it!
Well done! You've just finished deploying your very own highly-available MongoDB replica set on AWS! Let me know if this helped you!